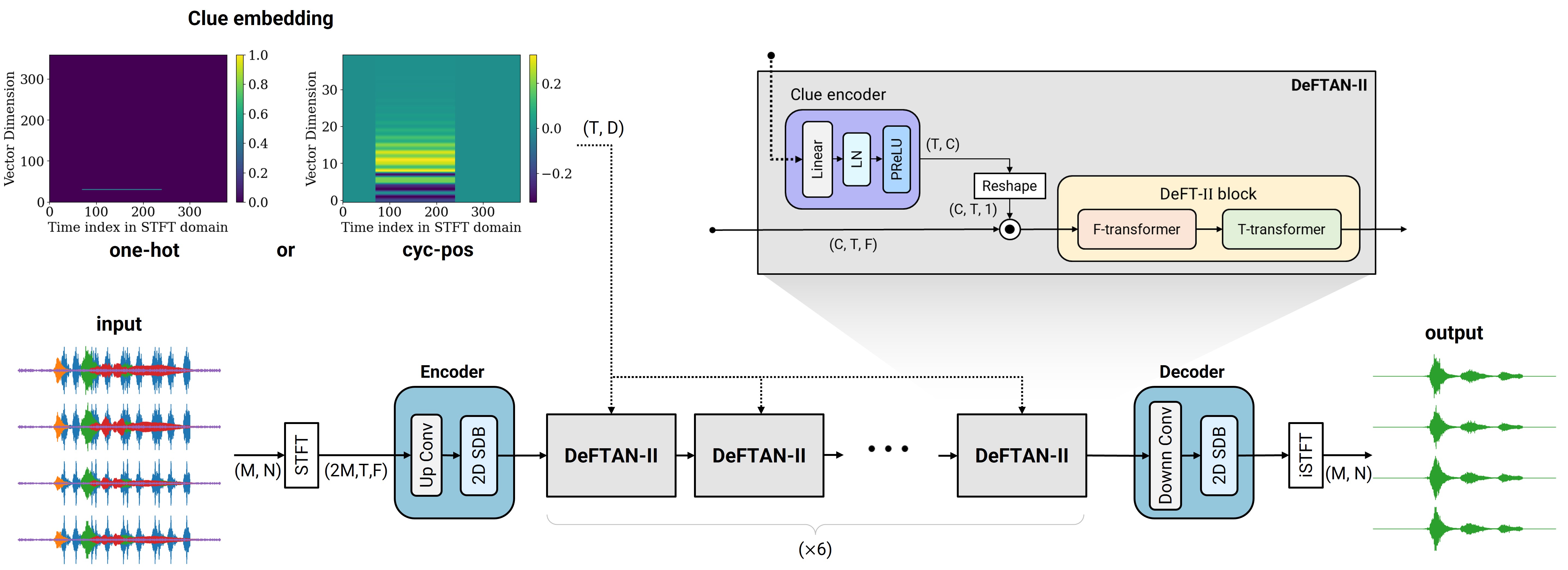
We propose a multichannel-to-multichannel target sound extraction (M2M-TSE) framework for separating multichannel target signals from a multichannel mixture of sound sources. Target sound extraction (TSE) isolates a specific target signal using user-provided clues, typically focusing on single-channel extraction with class labels or temporal activation maps. However, to preserve and utilize spatial information in multichannel audio signals, it is essential to extract multichannel signals of a target sound source. Moreover, the clue for extraction can also include spatial or temporal cues like direction-of-arrival (DoA) or timestamps of source activation. To address these challenges, we present an M2M framework that extracts a multichannel sound signal based on spatio-temporal clues.
We demonstrate that our transformer-based architecture can successively accomplish the M2M-TSE task for multichannel signals synthesized from audio signals of diverse classes in different room environments. Furthermore, we show that the multichannel extraction task introduces sufficient inductive bias in the DNN, allowing it to directly handle DoA clues without utilizing hand-crafted spatial features.
Model Architecture (M2M-TSE)
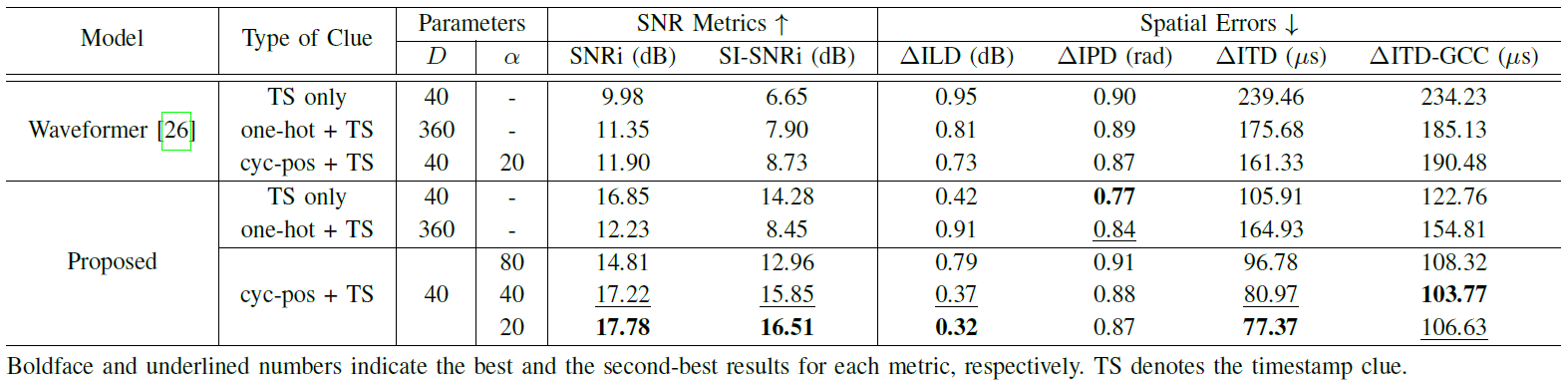
Performance Comparisons across TSE Models and Clues
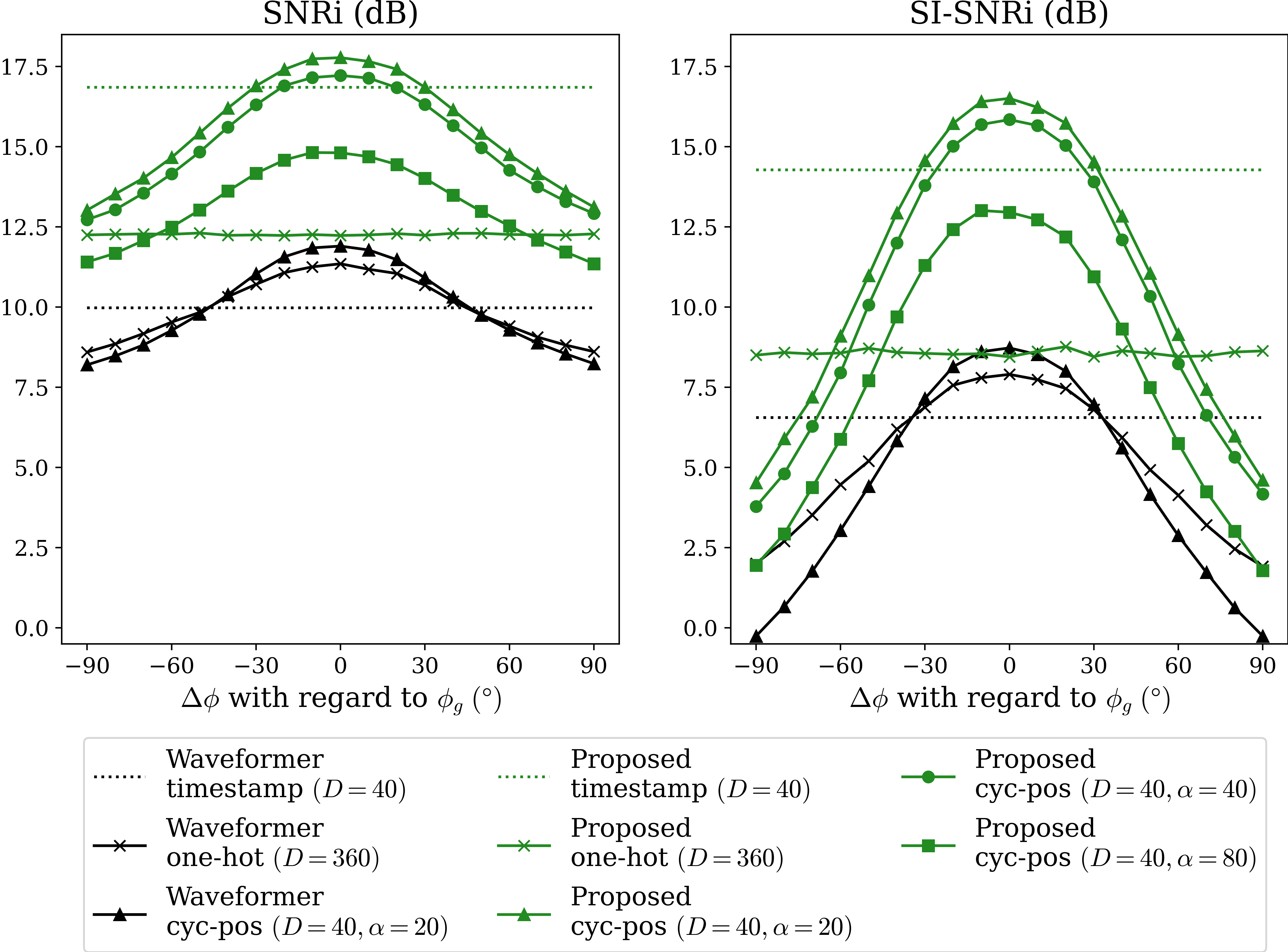
SNRi and SI-SNRi Change with respect to Target Azimuth Angle
Audio Samples
Click a toggle to listen to samples
Sample #1
Extract an audio in the direction of 251$^{\circ}$ from mixture in [6$^{\circ}$, 111$^{\circ}$, 207$^{\circ}$, 251$^{\circ}$]
Input Mixture
Ground Truth
Proposed (cyc-pos + TS, $D$=40, $\alpha$=20)
Proposed (cyc-pos + TS, $D$=40, $\alpha$=40)
Proposed (cyc-pos + TS, $D$=40, $\alpha$=80)
Proposed (one-hot + TS, $D$=360)
Proposed (TS, $D$=40)
Waveformer (cyc-pos + TS, $D$=40, $\alpha$=20)
Waveformer (one-hot + TS, $D$=360)
Waveformer (TS, $D$=40)
Sample #2
Extract an audio in the direction of 47$^{\circ}$ from mixture in [25$^{\circ}$, 47$^{\circ}$, 69$^{\circ}$, 207$^{\circ}$]
Input Mixture
Ground Truth
Proposed (cyc-pos + TS, $D$=40, $\alpha$=20)
Proposed (cyc-pos + TS, $D$=40, $\alpha$=40)
Proposed (cyc-pos + TS, $D$=40, $\alpha$=80)
Proposed (one-hot + TS, $D$=360)
Proposed (TS, $D$=40)
Waveformer (cyc-pos + TS, $D$=40, $\alpha$=20)
Waveformer (one-hot + TS, $D$=360)
Waveformer (TS, $D$=40)
Sample #3
Extract an audio in the direction of 321$^{\circ}$ from mixture in [68$^{\circ}$, 179$^{\circ}$, 270$^{\circ}$, 321$^{\circ}$]
Input Mixture
Ground Truth
Proposed (cyc-pos + TS, $D$=40, $\alpha$=20)
Proposed (cyc-pos + TS, $D$=40, $\alpha$=40)
Proposed (cyc-pos + TS, $D$=40, $\alpha$=80)
Proposed (one-hot + TS, $D$=360)
Proposed (TS, $D$=40)
Waveformer (cyc-pos + TS, $D$=40, $\alpha$=20)
Waveformer (one-hot + TS, $D$=360)
Waveformer (TS, $D$=40)
Sample #4
Extract an audio in the direction of 330$^{\circ}$ from mixture in [3$^{\circ}$, 46$^{\circ}$, 330$^{\circ}$]